
Powerful yet easy to use
Superset makes it easy to explore your data, using either our simple no-code viz builder or state-of-the-art SQL IDE.
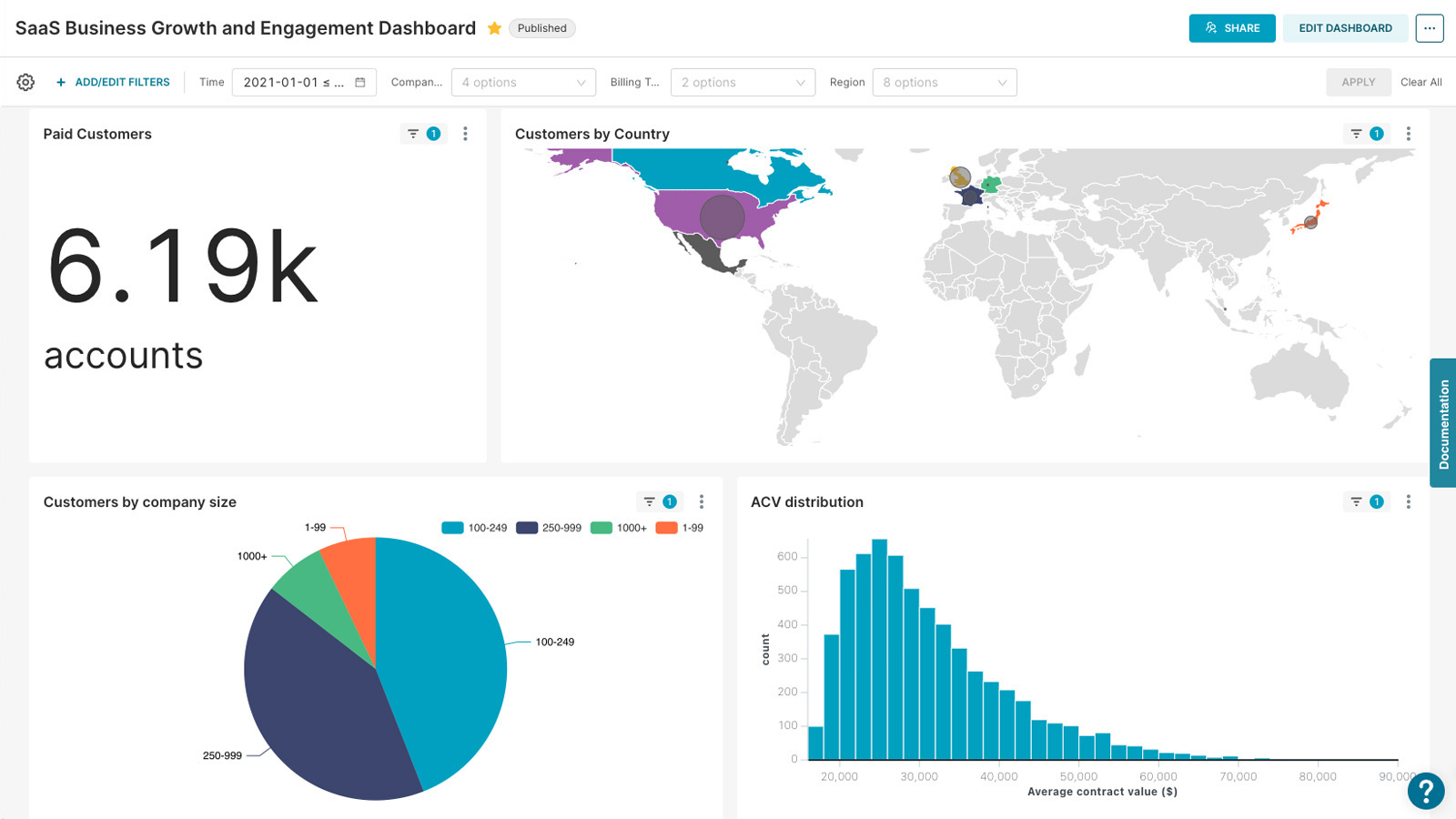

Superset is fast, lightweight, intuitive, and loaded with options that make it easy for users of all skill sets to explore and visualize their data, from simple line charts to highly detailed geospatial charts.

Superset makes it easy to explore your data, using either our simple no-code viz builder or state-of-the-art SQL IDE.

Superset can connect to any SQL-based databases including modern cloud-native databases and engines at petabyte scale.

Superset is lightweight and highly scalable, leveraging the power of your existing data infrastructure without requiring yet another ingestion layer.

Superset ships with 40+ pre-installed visualization types. Our plug-in architecture makes it easy to build custom visualizations.





















